The code that prints the condominium listing is structured roughly similar to the example you saw in the previous section that printed all of the nodes of a document. However, in this case there is no recursion because you aren't "walking" the document tree. Instead, you pluck out nodes of a particular type and then print them. For example, you know that all nodes corresponding to the <name> tag contain project names. So, to print the name of a project just grab the array of <name> tags and print each of them out. This technique is used to print the name, address (two lines), and image for each condominium project.
Listing 16.5 contains the complete code for the condominium list example web page.
Listing 16.5. An HTML Page That Prints the Condominium Document as a Formatted List
1: <html>
2: <head>
3: <title>Condominium List</title>
4: <script type="text/javascript">
5: var xmlDoc;
6: function loadXMLDoc() {
7: // XML loader for IE
8: if (window.ActiveXObject) {
9: xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
10: xmlDoc.load("condos.xml");
11: printCondos();
12: }
13: // XML loader for other browsers
14: else {
15: xmlDoc = document.implementation.createDocument("", "", null);
16: xmlDoc.load("condos.xml");
17: xmlDoc.onload = printCondos;
18: }
19: }
20:
21: function printCondos() {
22: var nameNodes = xmlDoc.getElementsByTagName("name");
23: var addrNodes = xmlDoc.getElementsByTagName("address");
24: var addr2Nodes = xmlDoc.getElementsByTagName("address2");
25: var imgNodes = xmlDoc.getElementsByTagName("img");
26: for (var i = 0; i < nameNodes.length; i++) {
27: document.write("<div style='font-family:arial; font-weight:bold;
28: color:maroon'>" + nameNodes[i].firstChild.nodeValue +
29: "</div>");
30: document.write("<div style='font-family:arial'>" +
31: addrNodes[i].firstChild.nodeValue + "<br />");
32: document.write(addr2Nodes[i].firstChild.nodeValue + "</div>");
33: document.write("<img src='" + imgNodes[i].firstChild.nodeValue +
34: "' alt='" + nameNodes[i].firstChild.nodeValue + "' /><hr />");
35: }
36: }
37: </script>
38: </head>
39:
40: <body onload="loadXMLDoc()">
41: </body>
42: </html>
This code starts out familiar in that it relies on the loadXMLDoc() function to load the condos.xml document (lines 9, 10, 15, and 16), as well as calling the printCondos() function to print the relevant document content (lines 11 and 17). The printCondos() function is where all the action takes place.
The printCondos() function starts off by extracting four arrays of nodes from the XML document (lines 22 to 25). Each of these arrays corresponds to a certain tag in the document. For example, the project names that are coded using the <name> tag in the XML document are grabbed as an array of nodes by calling the DOM's getElementsByTagName() function (line 22). The name of the tag is passed into the function, and the result is an array containing elements that match that tag name.
After the four arrays of elements are extracted, a loop is created that iterates through each element and prints it to the page (lines 26 through 35). Even the image associated with each condo is printed, and its resulting HTML <img> tag is coded to include the project name in the required alt attribute so that when you hover the mouse over the image in a web browser the name of the project will appear. Speaking of viewing the page in a web browser, Figure 16.4 shows the results of this script in Mozilla Firefox.
Figure 16.4. All of the condominiums in the condos.xml document are printed as a formatted list.
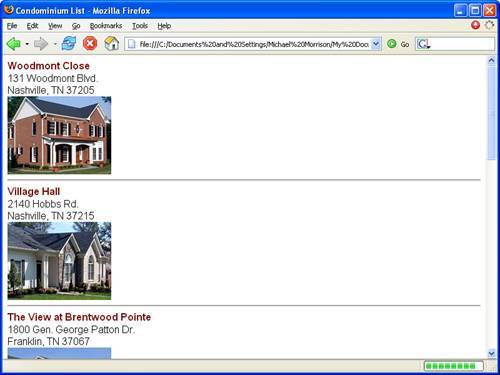
The figure reveals how the condominium list is formatted on an HTML page as a vertical sequence. You could just as easily modify the script so that the condos are arranged in a table or in some other layout that suits your particular needs. The point is that the DOM allows you to access the XML data and render it to an HTML web page any way you want.