HTML links (hyperlinks) are based upon the concept of connecting one resource to another resourcea source is linked to a target. The source of an HTML link is typically displayed on a web page (via text or an image) so as to call out the fact that it links to another resource. Text links are typically displayed with an underline, and the mouse pointer usually changes when the user drags it over a link source. Traversing a link in HTML typically involves clicking the source resource, which results in the web browser navigating to the target resource. This navigation can occur in the same browser window, in which case the target resource replaces the current page, or in a new browser window.
The important thing to understand about HTML links is that although they involve two resources, they always link in one direction. In other words, one side of the link is always the source and the other side is always the target, which means you can follow a link only one way. You might think that the Back button in a web browser allows HTML links to serve as two-way links, but the Back button has nothing to do with HTML. The Back button in a web browser is a browser feature that involves keeping a running list of web pages so that the user can back through them. There is nothing inherent in HTML links that supports backing up from the target of a link to the source; the target of a link knows nothing about its source. So, HTML links are somewhat limited in that they can link only in one direction. You might be wondering how it could possibly be useful to link in two directionswe'll get to that in a moment.
It's worth pointing out that many of the conventions we've come to expect in terms of HTML linking aren't directly related to HTML. For example, an HTML link doesn't specify anything about how it is to be displayed to the user (colored, underlined, and so forth). It is up to stylesheets, browsers, and user preferences to determine how links are presented. Although this may not seem like a big deal right now, the browser's role in displaying links may become more significant if and when browsers support XLink. This is because XLink supports links between multiple resources and in multiple directions, which makes them difficult to visualize with a simple underline or mouse pointer.
If you've spent any time coding web pages with HTML, you're no doubt familiar with the a element, also known as the anchor element, which is used to create HTML links. The anchor element identifies the target resource for an HTML link using the href attribute, which contains a URI. The HRef attribute can either reference a full URI or a relative URI. HTML links can link to entire documents or to a document fragment. Following is an example of an HTML link that uses a relative URI to link to a document named fruit.html:
Click <a href="fruit.html">here</a> for fruit!
This code assumes the document fruit.html is located in the same path as the document in which the code appears. If you want to link to a document located somewhere else, you'll probably take advantage of a full URI, like this:
Click <a href="http://www.xyz.com/veggies.html">here</a> for veggies!
Document fragments are a little more interesting in terms of how they are linked in HTML. When linking to a document fragment, the href attribute uses a pound symbol (#) in between the URI and the fragment identifier. The following is an example of how you create an HTML link to a specific location within a document:
Click <a href="fruit.html#bananas">here</a> for bananas!
In this code, the fragment identifier bananas is used to identify a portion of the fruit.html document. You associate a fragment identifier with a portion of a document using the anchor element (a) and the id attribute in the link target. This attribute value is the name used to the right of the pound symbol (#) in the anchor element that serves as the link source. Following is an example of an HTML link that establishes a banana document fragment for a link target:
<a >We have the freshest bananas for $0.99 per pound.</a>
This code shows how a sentence of text can be marked as a link target by setting the id attribute of the a tag with a unique fragment identifier.
If you're already an HTML guru, I apologize for boring you with this recap of HTML links. Boring or not, it's important to have a solid grasp of HTML links because they serve as the basis for simple XML links.
HTML links are both very useful and very easy to create. Simply based on the power and usefulness of the Web, it's hard to make an argument against the strength of HTML's simplistic approach to linking documents. However, there are many ways that it can be improved, some of which you might have never thought about. For one, it would be nice if links could be bidirectional, which means that you wouldn't be dependent on a browser's implementation of a Back button in order to navigate backwards to a previous resource. Although this may seem trivial, it could be extremely useful to be able to traverse a link in either direction, thereby eliminating the need for fixed source and target resources. A bidirectional link would treat the two resources as both sources and targets depending on the context.
In addition to bidirectional links, it could be extremely beneficial to have links that reference multiple target resources. This would keep web developers from having to duplicate content for the sole purpose of providing link sources. More specifically, a link with multiple targets could present a pop-up menu with the target selections from which the user selects. An example of this type of link might be a book listing on Amazon.com. A multiple-target link for the cover image of a book could present a pop-up menu containing links to documents such as a book summary, reviews, and a sample chapter. This tightens up the user interface for the web site by reducing the content used purely for navigational purposes. It also provides a logical grouping of related links that would otherwise be coded as unrelated links using HTML anchors.
If your only exposure to document linking is HTML, you probably regard link resources as existing completely separate of one another, at least in terms of how they are displayed in a web browser. XML links shatter this notion by allowing you to use links to embed resources within other resources. In other words, the contents of a target resource can be inserted in place of the link in a source document. Granted, images are handled much like this in HTML already, but XML links offer the possibility of embedding virtually any kind of data in a document, not just an external image. Traversing embedded links in this manner ultimately results in compound documents that are built out of other resources, which has some interesting implications for the Web. For example, you could build a news web page out of paragraphs of text that are dynamically pulled from other documents around the web via links.
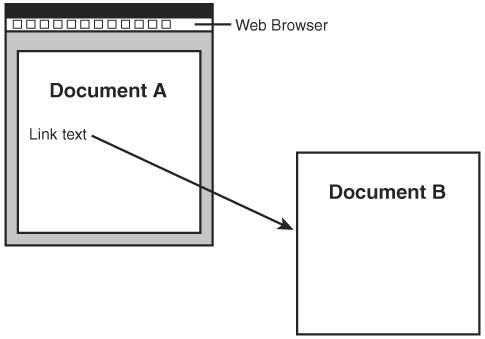
Speaking of link traversal, HTML links are limited in that the user must trigger their traversal. For example, the only way to invoke a link on a web page is to click the linked text or image, as shown in Figure 22.2.
Figure 22.2. In order to traverse an HTML link, the user must click on linked text or a linked image, which points to another document or resource.
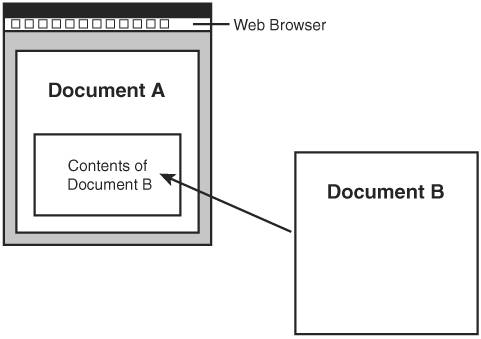
You may be wondering why it would be desirable to have it any other way. Well, consider the situation where a linked resource is to be embedded directly in a document to form a compound document. You might want the embedding to take place immediately upon opening the document, in which case the user would have nothing to do with the link being invoked. In this sense, the link is serving as a kind of connective tissue for components of a compound web document (see Figure 22.3), which is far beyond the role of links in HTML. Again, images already work like this in HTML via the img tag, but XML links open the door for many other possibilities with flexible linking.
Figure 22.3. XML links are flexible enough to allow you to construct compound documents by pulling content together from other documents.
As you're starting to see, XML links, which are made possible by the XLink technology, are much more abstract than HTML links, and therefore can be used to serve more purposes than just providing users a way of moving from one web page to the next. Admittedly, you almost have to take a few steps back and think of links in a more abstract sense to fully understand what XML links are all about. The up side to this shift in thinking is that when the significance of XLink fully sinks in, you will probably view the web quite differently.
The problem at the moment is that XLink has been brutally slow to catch on, and only has limited support in Firefox and no support in Internet Explorer or any other browser. So the pie in the sky features of XLink are unfortunately still in the realm of the hypothetical, at least in terms of the Web.
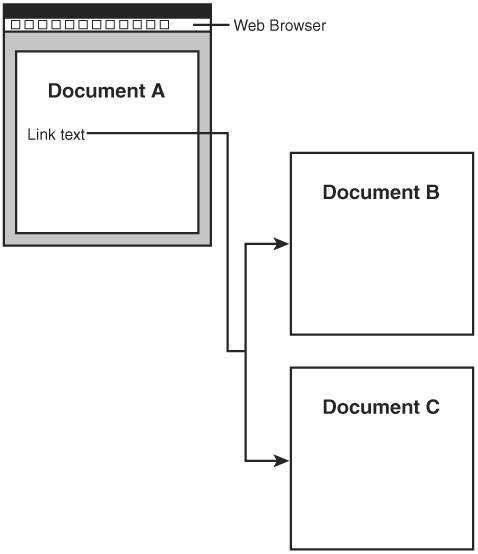
Yet another facet of XLink worth pointing out is its support for creating links that reside outside of the documents they link. In other words, you can create a link in one document that connects two resources contained in other documents (see Figure 22.4). This can be particularly useful when you don't have the capability of editing the source and target documents. These kinds of links are known as out-of-line links and will probably foster the creation of link repositories. A link repository is a database of links that describe useful connections between resources on the Web.
Figure 22.4. XML links allow you to do interesting things such as referencing multiple documents from a link within another document.
One example of a link repository that could be built using XLink is an intricately cross-referenced legal database, where court cases are linked in such a way that a researcher in a law office could quickly find and verify precedents and track similar cases. Though it's certainly possible to create such a database and incorporate it into HTML web pages, it is cumbersome. XLink provides the exact feature set to make link repositories a practical reality.
One of the side benefits of out-of-line links is the fact that the links are maintained separately from the documents that they link. This separate storage of links and resources makes it possible to dramatically reduce broken links, which are otherwise difficult to track down and eliminate.
You now understand that XML linking is considerably more powerful than its HTML counterpart. Perhaps more interesting is the fact that XML links involve a concert of technologies working together. XLink is the primary technology that makes XML links possible, but it requires the help of two other technologiesXPointer and XPath. If you traced the history of XLink in the W3C, you'd learn that it originally consisted of only two components, XPointer and XLink. However, the W3C realized that XPointer wasn't the only XML technology that needed a means of addressing parts of a document. XSLT also needed a means of addressing document parts, so it was decided to separate document addressing into XPath. XPointer builds on XPath to provide support for addressing the internal structure of XML documents. XLink in turn uses XPointer to describe flexible links to specific structures within XML documents.
XLink is designed to support simple one-way links similar to those in HTML, as well as a variety of different extended links that offer interesting new ways of linking documents. XLink is implemented as an XML language, which means that it can be easily integrated into XML applications. XPointer is a non-XML language based upon XPath that is used to address internal structures in XML documents. XPointer is an important part of XLink because it specifies the syntax used to create fragment identifiers, which are used to reference internal document constructs.