If applications didn't use connections this way, they implemented some kind of connection pooling, wherein a pool of already-open connections was used to supply any application. This is because, although database connections are expensive, they are also finite. To begin with, if only for licensing reasons, we must usually manage them, but also each connection uses up memory on both client and server machines. Thus when certain database access technologies require multiple connections per user or application to carry out a task, they can severely impact application performance.
One of the interesting aspects of building middle-tier objects that talk to the database (rather than allowing an application on the client to open its own database connection) is that objects in the middle-tier can open the connections. They might even be on the same machine as the database server, and they can provide connection pooling. When Microsoft Transaction Server (MTS) was introduced as a middleware provider of both Object Request Brokering services and Transaction Process Monitoring, one of its subsidiary roles was to provide pooling of shared resources. Currently ODBC connection pooling is already provided by MTS. Even without MTS, ODBC 3.5 now provides connection pooling itself. (See Figure 12-1.)
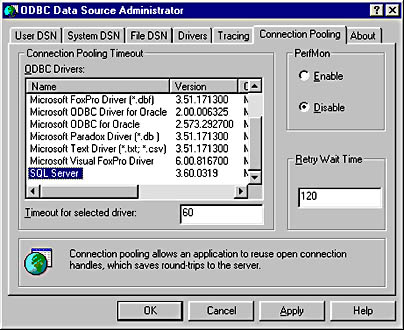
Figure 12-1 Connection pooling with ODBC 3.5
The effect of connection pooling can best be seen by a project that opens components, which each open and use a connection.
With connection pooling in place it becomes viable to change the connection opening and holding strategy. It can even be worthwhile to open a connection every time one is required, use it, and then close it, because in reality the connection will not be opened and closed but pooled, so as to avoid the cost of repeated connection openings. However, the pool can be limited in size so that the minimum number of active useful connections exist, but idle connections using resources without doing work are all but eradicated.